上个月我支付给安思罗皮克的 312 美元账单中,有 60% 源于一个单一的缺陷:模型上下文协议路由器缓存键中缺少租户标识符。
修复方法 literally 就是如此:
// 修复前
const cacheKey = `mcp:context:${requestId}`;
// 修复后
const cacheKey = `mcp:context:${tenantId}:${requestId}`;
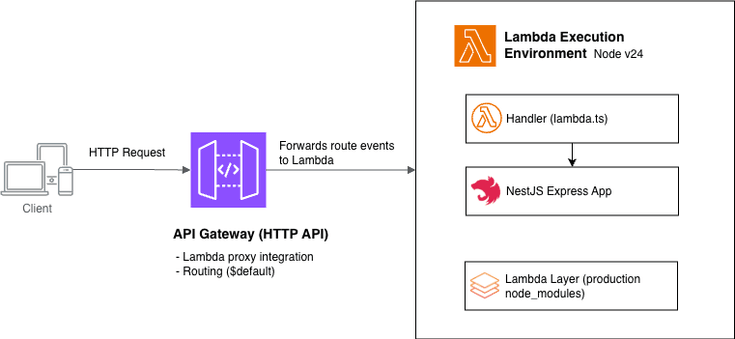
缺失的那一部分意味着处于热启动状态的云flare Worker 实例将广告主 A 的缓存向量化搜索结果提供给了广告主 B 的工具响应。这发生在一个生产环境的广告分析软件即服务系统中,而非演示环境。
反直觉之处在于:我曾假设 V8 隔离区边界能保护我。但事实并非如此——至少不像大多数人认为的那样。隔离区级别的隔离适用于不同的 Worker 部署之间,而不适用于命中同一个热启动 Worker 实例的两个并发请求之间。模块作用域的变量会在请求之间持久存在。因此,任何在模块级别初始化的上下文管理器或缓存对象都是共享状态,即使在 Worker 上也是如此。
这种故障模式非常隐蔽,耗费了 6 周时间才找到。向量化查询量是预期的 3 倍——这是第一个信号。深入查看日志后,我发现租户 a9f2 的缓存命中结果被提供给了属于租户 b3c1 的会话。受损的缓存包含向量搜索结果,因此每次错误命中都会触发下游的重新获取链。这种级联效应导致了令牌支出的激增:错误的缓存数据 → 克劳德使用新鲜上下文重试 → 索内特输入令牌迅速累积。
在修复缓存键命名空间并添加一个在工具响应元数据中租户标识符不匹配时抛出错误的 PostToolUse 钩子后,索内特输入成本从每月约 187 美元降至约 94 美元。同期向量化查询量下降了约 40%。
对于使用类似技术栈的任何人,有一点值得注意:这个特定的修复方案——将所有内容限定为每个请求的 Worker ExecutionContext(执行上下文)——并不能干净地迁移到类似 Fly.io 上的长期运行的 Node 进程。在那里,AsyncLocalStorage(异步本地存储)才是正确的原语。直接移植 Worker 模式会给你一种虚假的安全感。
我在 riversealab.com 上撰写了完整的分析文章——包括 PostToolUse 钩子的实现、键值存储/数据库 1 缓存键强制模式,以及这种隔离设计显得过度的情况。
免责声明:本文内容来自互联网,该文观点不代表本站观点。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容,请到页面底部单击反馈,一经查实,本站将立刻删除。